
Anomaly Detection
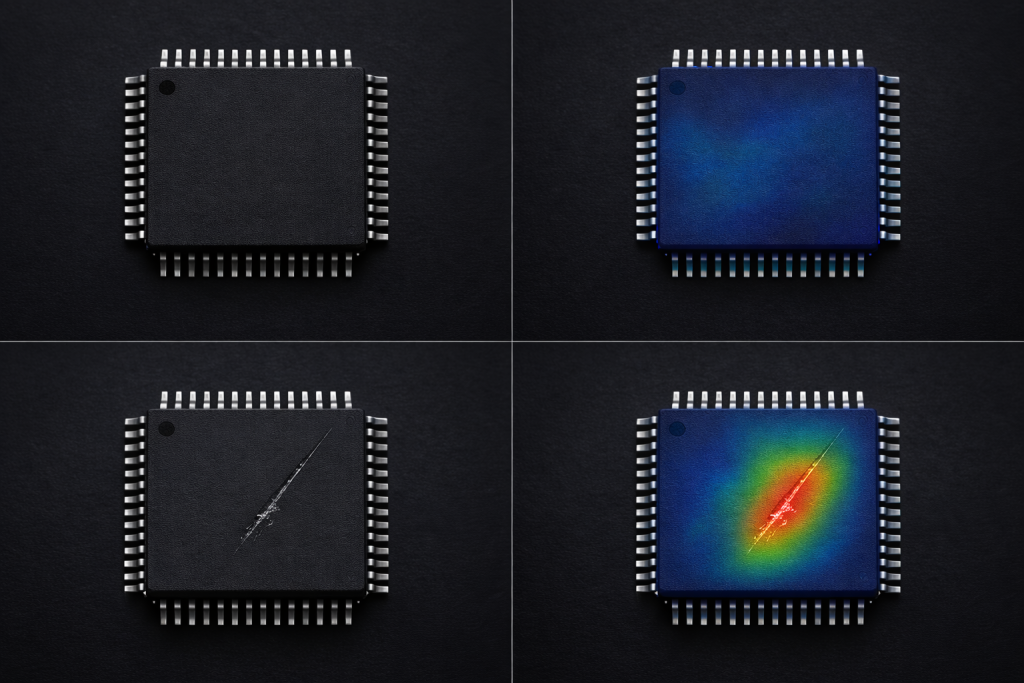
Anomaly detection is a fundamental problem in machine/deep learning and data analysis, aimed at identifying patterns that significantly deviate from expected or normal system behavior. Such anomalies often correspond to rare events, faults, security threats, or environmental changes and play a crucial role in ensuring the reliability, safety, and efficiency of modern technological systems. Our […]
Visual Knowledge Graphs & Multimodal LLMs

Our research group investigates the intersection of Large Language Models (LLMs), multimodal learning (with a focus on vision), and graph theory. We aim to build more intelligent, robust, and explainable AI systems capable of understanding and interacting with the world in a meaningful way. Potential topics: Visual Knowledge Graphs & LLMsOur research explores enhancing Large […]
Data & Evaluation (Fundamentals and Tools)

In computer science, building powerful AI models isn’t enough – we need to ensure they work reliably and fairly in the real world. Data & Evaluation is the field focused on making that happen. It covers two main parts: Datasets: This involves creating high-quality collections of data used to train and test AI models. It’s […]
FriendlyReality: la Virtual Reality al servizio dell’inclusività

Il progetto proposto mira a promuovere l’inclusione sociale delle persone diversamente abili tramite l’utilizzo di tecnologie immersive e interattive, come la Virtual Reality (VR) e i sistemi di hand tracking. L’obiettivo è sviluppare un software che permetta agli utenti di disegnare a mani libere modelli tridimensionali, che saranno poi inviati a un servizio di stampa […]